论文:An Interactive Method to Improve Crowdsourced Annotations
作者:Shixia Liu, Changjian Chen, Yafeng Lu, Fangxin Ouyang, Bin Wang
发表:IEEE VAST 2018
在一个图像分类的问题中,机器学习所产生的模型能够识别图片中的物体,给定一个合适的标记类别,如图 1 所示。训练一个这样的一个分类器就像教孩子们区分猫和狗一样,需要大量的已经带有标签的数据样本。我们以猫和狗为例,如果只让机器去标记图片,因为图片中猫和狗的很多特征都是相似的(例如四条腿,两只眼,甚至都会踹手手),往往得到的图片标记都会有很多错误。
图 1, 可以分辨出猫咪图片的分类器

图 2, 图片中很多特征是相似的,而且需要标记的图片也是海量的。
让领域专家来标记图片当然是一种比较稳妥的方法。但是需要标记的图片实在是太多了,如图 2 所示,领域专家很难独立完成成千上万图片的标记工作,耗时耗力。所以解决这一标记任务的通用思路是通过众包的方式,让更多的人来参与图片的标记工作。但是随着用户的增多,众包得来的标记数据质量很难得到保证。原因主要来自两方面:
标记用户的可信度,有的标记用户可能自己分不清不同类别的图片。更有甚者是随便标记的用户。
图片和类别的复杂性,如图 3 所示,类别和类别之间可能本身就难以分辨(萨摩耶和博美),有的图片中关键特征被遮挡了,或者图片本身的数据有干扰(例如豹子的图片出现在了猫的数据集中)。

图 3,标记任务所面临的挑战。
以往的工作关注于用可视分析的方法来交互式的标记数据或者对数据进行预处理。本文则是针对众包数据所得来的标记数据的质量问题,支持专家对标记数据和进行标记的用户进行评估,并且重新标记不确定的案例,通过可视化及交互手段迭代式的提高数据质量。本文所提出的方法流程(图 4)如下:
首先通过众包得到标记的数据集
然后通过图片的特征提取和众包数据,通过 Learning from Crowds 方法学习到每一幅图片所推荐的标记类别。本文用到的是-based model。
然后通过四个可视化界面的联动,包括类别矩阵,实例投影视图,用户可信度表格,和详情展示视图。允许用户分析数据集中不确定的实例和用户的行为,并对错误标记的图片进行纠正。
最后将纠正的结果应用于标记的数据集并迭代的更新相应的可视化界面和数据,达到数据质量的逐步提升。
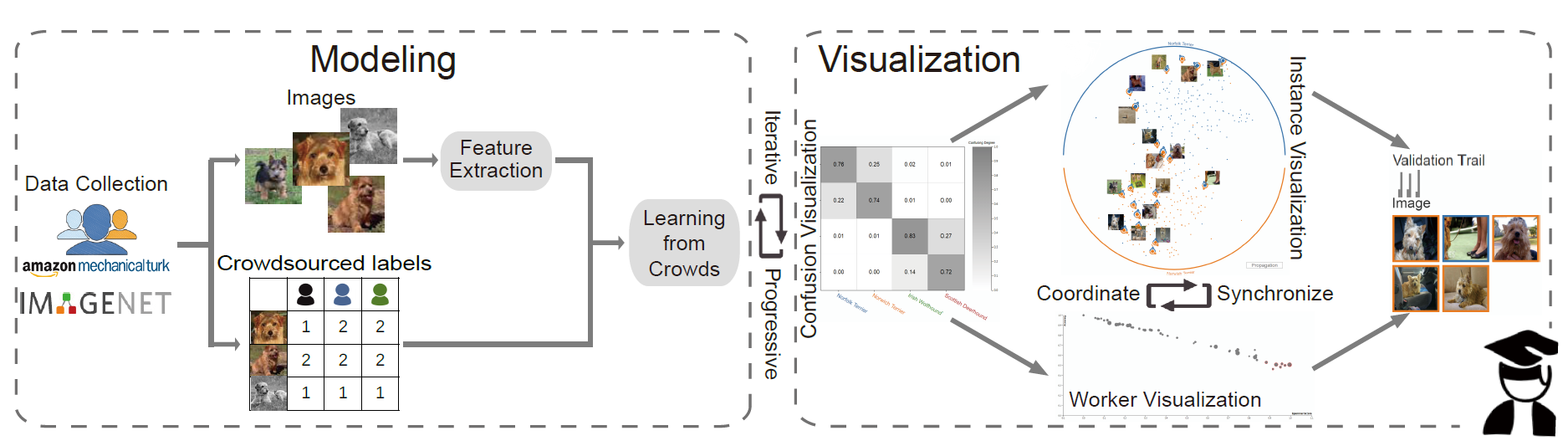
图 4, 方法的流程图
下面我们通过一个简单的案例,介绍系统的可视化方法。例子中用到了 65 位用户标记的共 2000 幅鸟的类别的数据,得到共 21825 个标记数据实例。系统通过标记数据和原始图片使用模型进行训练并得到了初始的标记结果。
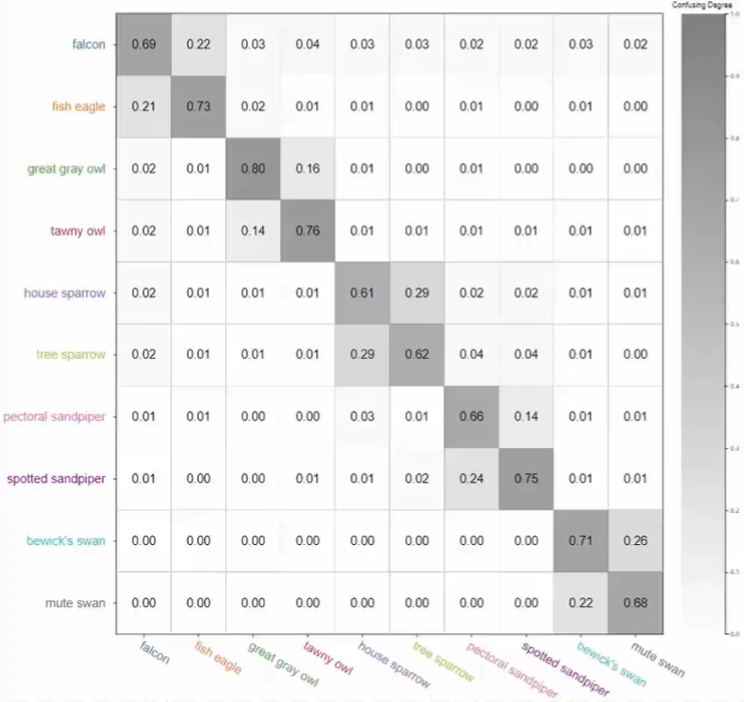
系统中第一个视图是类别之间的混淆矩阵。其中纵坐标是用户的标记,而横坐标是系统-based model 所进行的标记类别。每一个单元格中的数值表示用户和模型标记的匹配程度。例如左上角的 0.69 表示用户将图片标记成 falcon 类别的时候,模型有百分之六十九也标记成了 falcon。这样一来如果用户和模型标记完全符合,那么矩阵应该是一个对角矩阵。如果不是对角矩阵而出现了块状结构,那么说明用户对于其中的类别和模型给出的结果有一定的偏差,即用户对这些类别的图片有混淆的情况。例如下图中,我们可以看出一共有五个块,说明用户对于这五个块的每一对类别都有认知混淆的情况。而其他单元格内的数值都很小,说明用户不会混淆这五组之间两两的图片。
第二个视图是实例的投影视图,他将每一个图片都投影为二维平面上的一个点。外围的每一个圆弧都表示一个类别,并用颜色区分。图片按照标记的不确定性进行了排序,其中最不确定的图片用特殊的图案进行了编码,如下图中的 B 所示,这个图案表示一个图片,中间的圆点的颜色表示-based model 对他的标记类别,而外面的扇形表示用户对这个图片的标记类别,圆弧的宽度表示标记成这一类别的人数的多少。箭头指向类别对应的最外围的圆弧的方向。这一图案配以原始图片,直观的展示了用户和模型的标记结果,方便专家分析和重新标记。其他图片用圆点表示,圆点的颜色表示-based model 对于该图片的标记。
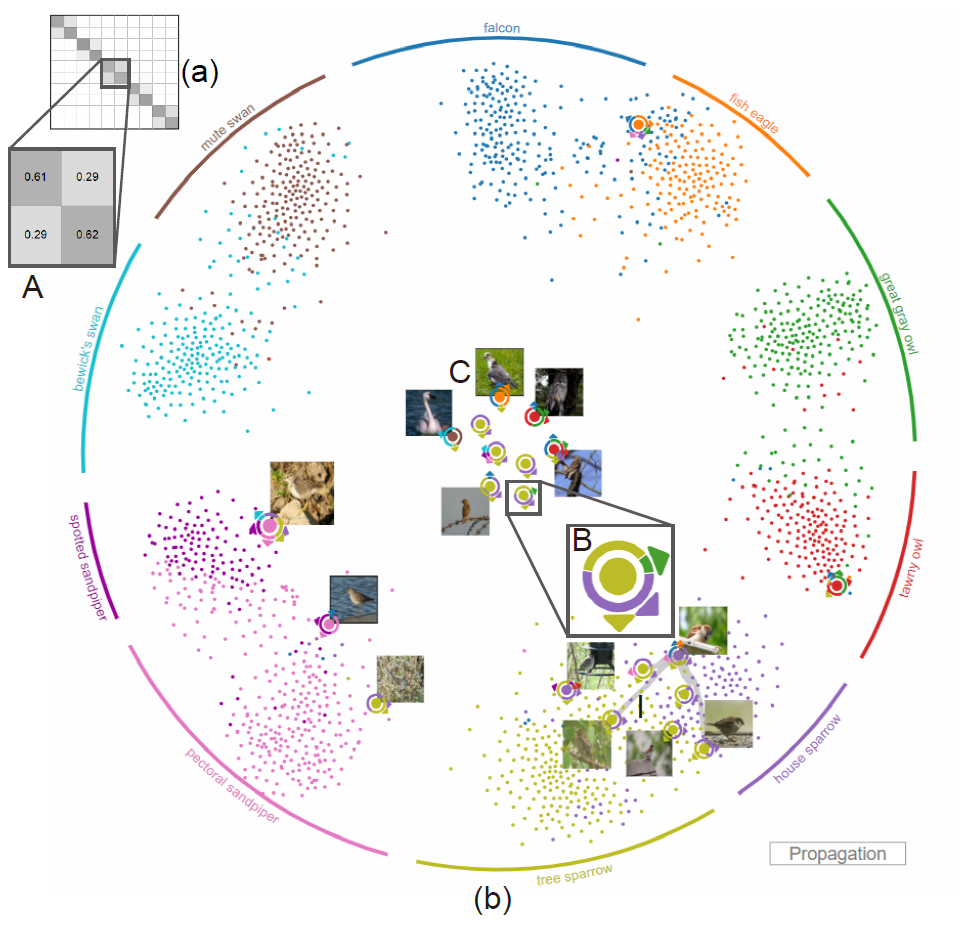
为了生成这样的一种投影结果,本文提出了一种基于 cost 函数的 t-SNE 投影方法,该方法的核心是优化如下的 cost 函数,其中第一项将不同类别的点分开,提高了整体的可读性,第二项用外围的圆弧吸引对应类别的点,最后一项则保证了两次投影结果的稳定性,使得两次投影结果中类别不变的点不动,而类别改变的点只进行轻微的移动。

剩下的两个视图展示了用户的可靠性和详细的图片信息。
在用户可靠性图表中,每一个用户是一个点,纵坐标表示用户标记的准确性,这里将-based model 标记的结果当做标准值。而横坐标是用户的欺诈行为得分。
详细视图中展示了用户选择的图片详情。例如下图展示了左上角用户所标记的五个图片。
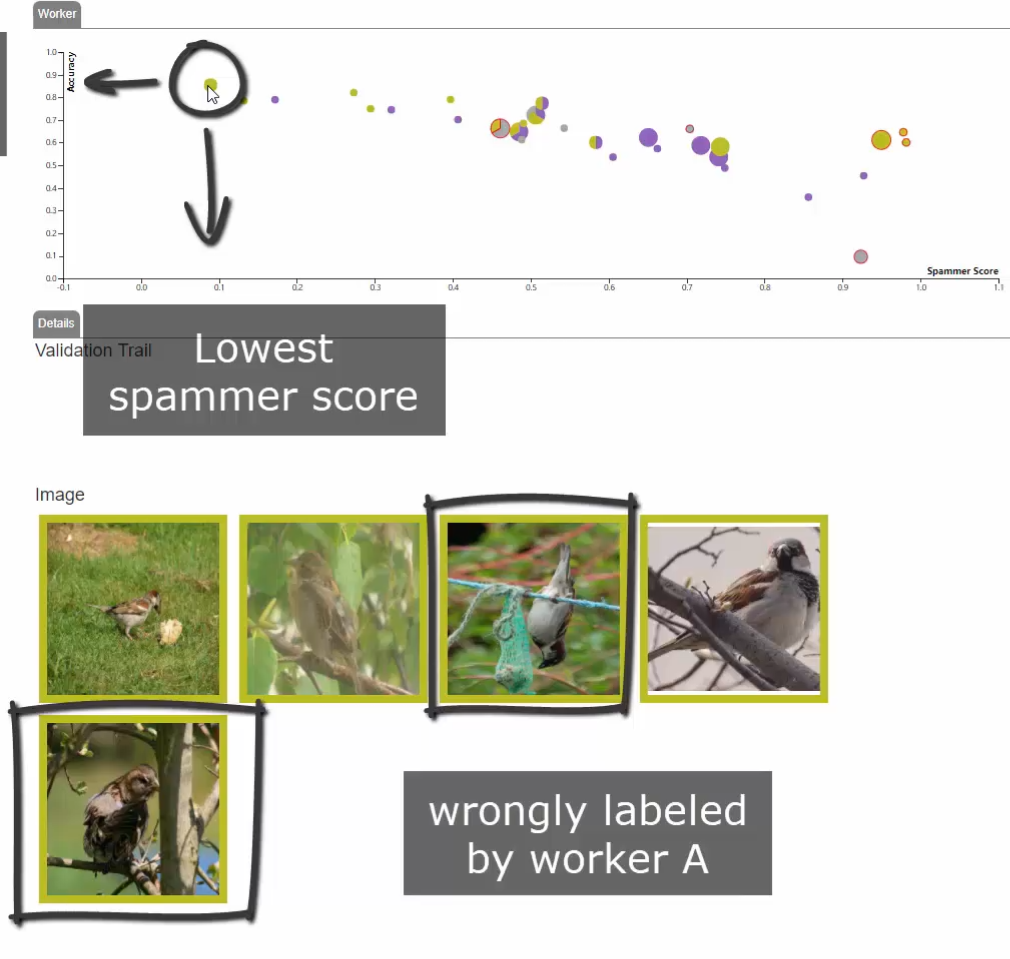
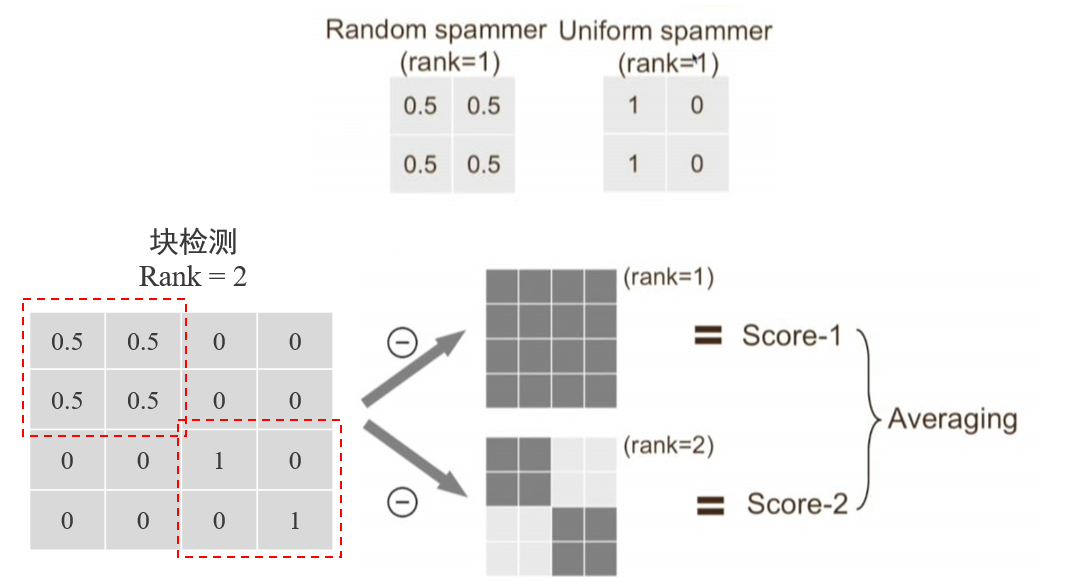
用户的准确度很好计算,那么如何得到用户的欺诈行为得分呢?本文扩展了之前的方法计算混淆矩阵到秩 1 矩阵距离的方法。考虑到用户可能仅对其中的几类图片有认知困难的情况,方法首先对用户标记和-based model 标记的混淆矩阵进行块检测,然后计算它到秩 1 至秩 N 矩阵的距离,并求平均作为最终的欺诈行为得分。
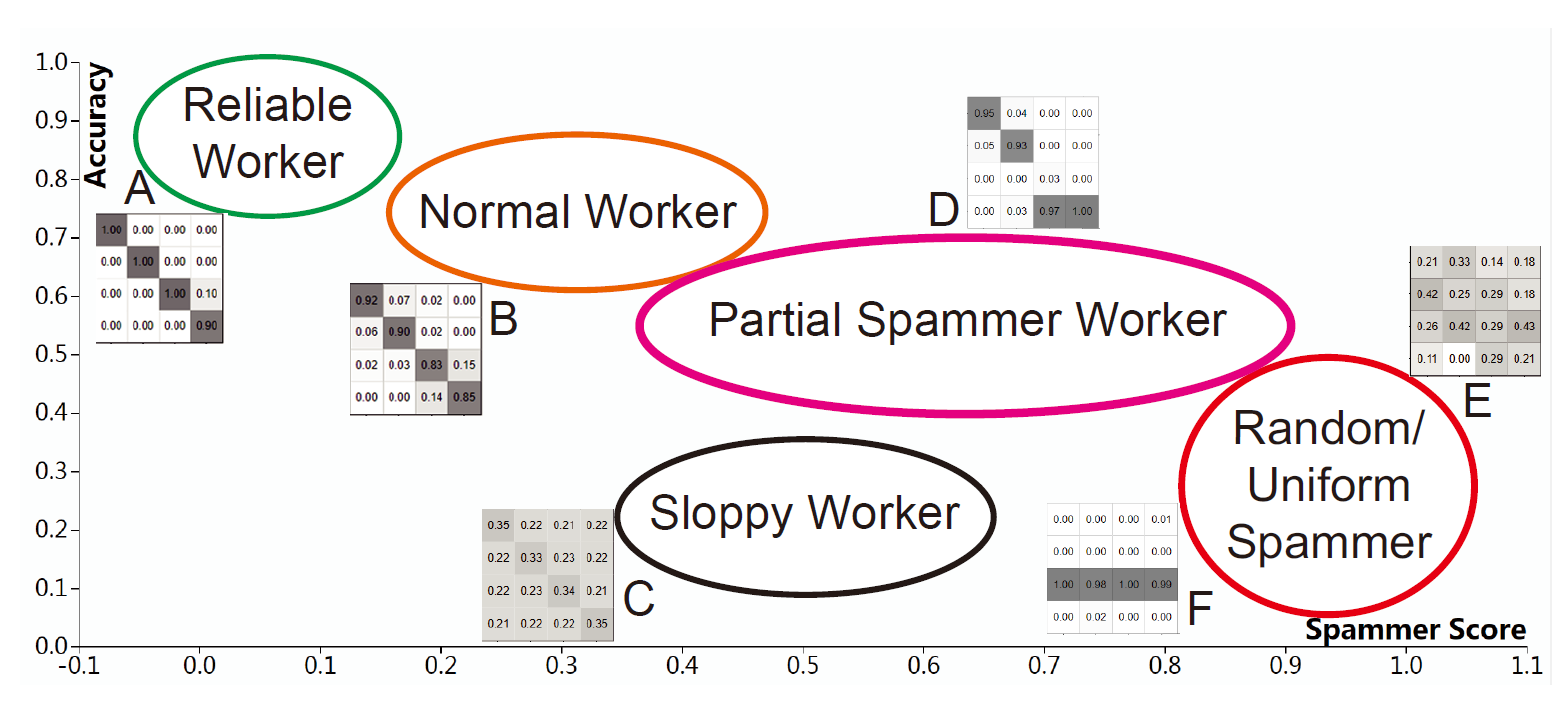
根据用户可靠性图表,我们可以大致的吧用户分为五个类别,
可靠用户
正常用户(有少量错误)
部分混淆用户(对于部分类别有混淆)
糊涂用户(仅仅能微弱的区分几个类别)
随机用户和统一用户(完全随机标记或把所有图片标记成同一类别)
通过上述 4 个视图,用户可以了解到标记数据的整体和详细信息,并对感兴趣的用户进行分析,或对不确定的图片进行重新标记。标记后的结果将会更新可视化界面,并迭代的逐步提升标记数据的数据质量。通过该系统,专家只需要很少的重新标记操作就可以有效率的提高众包得到的标记数据质量。最终只操作了 3%的数据就将该数据集的质量从 82.05%提高到了 89.05%。对比原始的-based model,减少了 7%的数据操作。

作者也提到了本文研究的未来方向:
Scalability 的问题:当图片更多时,t-SNE 投影视图可以采用采样的方法进行展示,减少计算和展示负荷
错误标记的问题:现在的系统假设专家的标记都是正确的。然而并不一定。所以多专家的合作系统值得期待。
有代表性的用户及实例的过滤提取:更加完善的推荐系统能够进一步减少专家的操作。
✉️ zhaosong_huang@zju.edu.cn